Web scrapper en c#
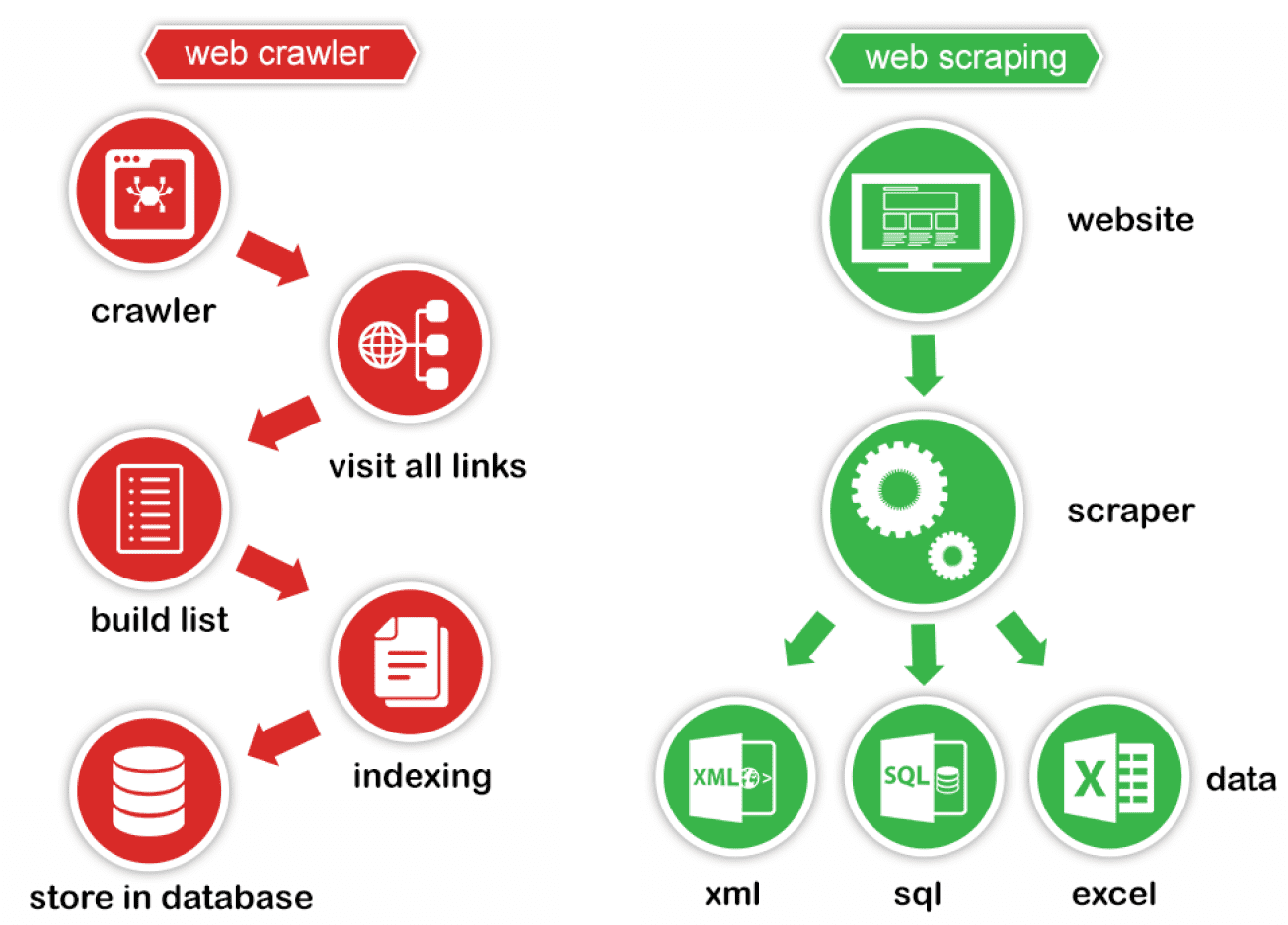
Un web scrapeur peut être définit comme un robot d’exploration web. l’objectif est de récupérer les données d’un site en particulier
 written by Yanis Legrand - Published on: 2022-03-18
written by Yanis Legrand - Published on: 2022-03-18Qu’est-ce qu’un web scraper ?
Un web scrapeur peut être définit comme un robot d’exploration web. l’objectif est de récupérer les données d’un site en particulier (contrairement au crawler, il est paramétré pour un site en particulier).
Est-ce légal ?
Cette pratique est dans un flou juridique, il faut donc veiller à ne pas réduire les performances du site visé (DDOS, ou ralentir le site dû à un nombre de requêtes conséquent).
L’objectif est de récolter des informations, cependant il faut faire attention à l’usage des données.
Selon le site islean-consulting.fr :
“Le sujet est même éminemment complexe. Voici une mise en situation pour s’en convaincre : un internaute ou une entreprise produit et publie sur internet un ensemble d’articles. Les articles sont scrapés par un tiers et re-publiés sans modification.
Dans ce cas précis le droit d’auteur entre en oeuvre en France et dans la grande majorité des pays du monde. Mais ce droit varie entre les pays. En France et en Europe, le droit sui generis stipule qu’un “investissement substantiel” doit être réalisé pour qu’une base de données (notamment de contenus) soit protégée par le droit d’auteur.
De ce fait, le scraping et la restitution d’une base de donnée scrapée sont en violation du code de propriété intellectuelle (Article L342-1) sous réserve que la transformation réalisée sur les données ne soit pas suffisamment substantielle pour justifier que la nouvelle base soit elle-même sui generis c’est à dire « de son propre genre » .”
Quand et pourquoi utiliser un web scraper ?
Selon le site rgdesign.fr/
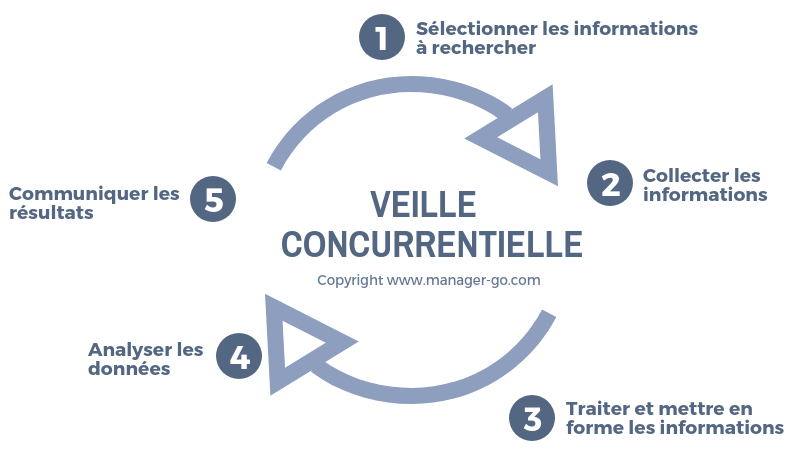
“L’intérêt principal du web scraping est de pouvoir récolter du contenu sur un site web, qui ne peut être copié collé sans dénaturer la structure même du document. Ainsi cette technique est souvent utilisée dans le cadre d’une veille concurrentielle, notamment sur des sites e-commerce.”
Fonctionnement
Il y a plusieurs moyens de pratiquer le scraping :
manuellement (une personne fait des recherches et effectue généralement des copiés collés de ce qui l’intéresse). automatiquement (un script qui analyse la page web et récupère automatiquement les données souhaitées).
La méthode qui nous intéresse est évidemment l’automatique.
Cas concret
situation :
J’aimerais être en freelance, mais le temps à rechercher, lire et sélectionner les annonces de missions est trop long. J’effectue ma recherche sur le site www.freelance-info.fr et souhaite automatiser cette tache grâce au scraping.
Préparation
Pour répondre à notre problématique, nous commençons par analyser notre cible.
Dans un objectif de simplification, je n’aborderai pas le sujet du stockage des données récoltées et n’expliquerai pas l’entièreté du processus (l’objectif étant de comprendre le principe et l’utilité du scraping).
À l’arrivée sur le site, il y à déjà deux actions à effectué pour accéder aux offres de missions :
- missions
- offres de missions

En observant, nous pouvons voir que nous avons accès aux missions grâce à l’URL suivante :
https://www.freelance-info.fr/missions?page=1
Cela réduit déjà les actions à effectuer par le scraper, nous pourrons donc charger notre page et commencer notre scraping à partir de cet URL.
La page des missions se présente ainsi, il faut donc analyser cette page grâce à l’inspecteur d’élément du navigateur (f12 sur chrome) :
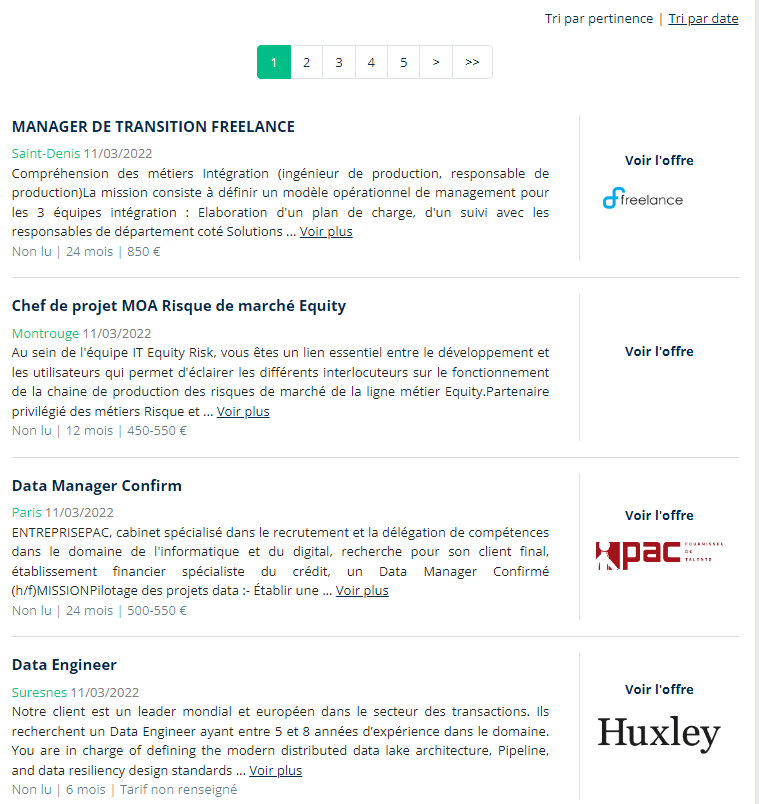
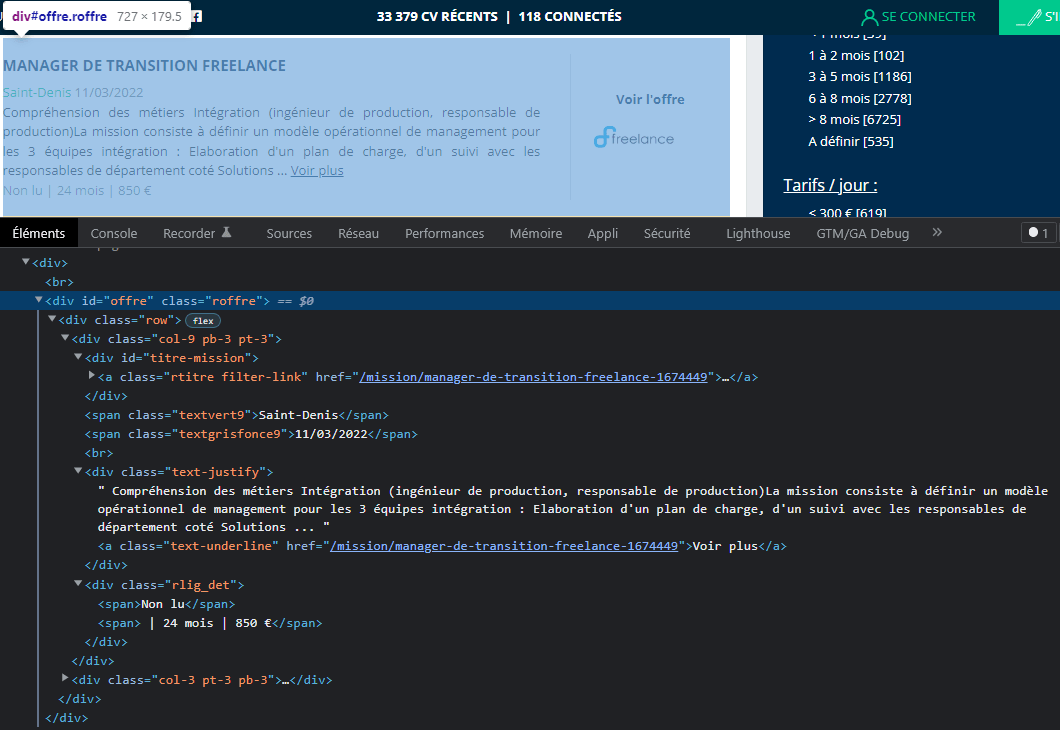
Les informations qui nous intéressent sont :
- Le titre
- le lieux
- la date
- la description
- l’entreprise
- la durée
- l’indication “Non Lue” ou “Lu”
Maintenant que nous avons l’URL à scraper, ainsi que les données ciblées, nous pouvons commencer à programmer.
Élaboration du scraper
Nous allons faire le scraper en C# à l’aide de la librairie HTML Agility Pack https://html-agility-pack.net/
Cette librairie est spécialement conçue à cet usage et est donc relativement simple à utiliser.
Voici les étapes que je me suis fixé pour faire mon scraper. Dans mon cas, l’élaboration des schémas et MCD était déjà réalisés.
- Se renseigner sur HTML Agility Pack, Asp .net, linq et where ainsi que le moyen de stockage choisi pour les donnés.
- Faire des premiers essais simples, en console (une sorte de maquette qui ne stock aucune donnée).
- Trouver un moyen de stocker les données
- Créer une structure web (MVC ou API) et y intégrer le scraper
Pour m’aider dans ce projet, j’ai suivi les documentation officielles de Microsoft, HTML A Agility Pack ainsi que des vidéos trouvés sur internet.
Documentation HTML A Agility Pack
Développé une application web en c# (MVC)
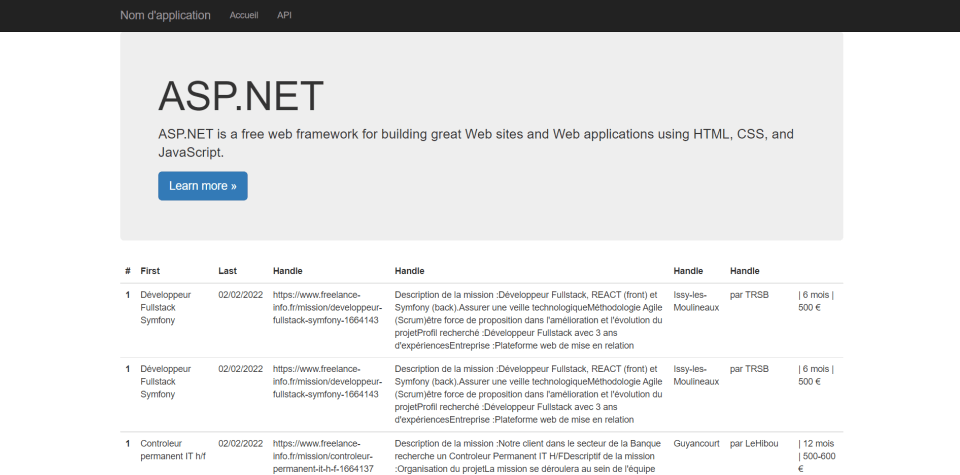
Resultat
Les filtres appliqués sont les suivant :
- Date maximale de l’annonce : 2 jours
- une liste de mots obligatoire : Développeur, JS, JavaScript, c#
- Télétravail obligatoirement
Conclusion
Un web scraper peut être utile dans certains cas (veille concurrentielle, technologique ou sur un marché en particulier).
En faire un a été très formateur, car son développement a touché beaucoup de principe C#.
J’ai eu que six semaine pour le réalisé, ce qui m’à forcé à m’organisé (chose qui pour moi étais complètement abstrait au paravent).
Ce fut donc pour moi un grand pas en avant dans le monde de la programmation.